Interest in KM is also being driven by its ability to help companies achieve many of their top enterprise servicing goals: improving productivity, increasing the use of self-service, decreasing customer effort, reducing operating costs, improving cross-departmental coordination, increasing customer and staff engagement, and delivering a better, more personalized customer experience.
This is a major and long overdue turnaround for the KM, which has taken many years to catch the attention of organizations. The question that organizations are now asking is whether KM solutions are able to meet their needs in the era of digital transformation.
KM Awakening
The new generation of KM solutions, many of which are relatively new market entrants, are either up to the digital challenge or are benefiting from investments to get them there. These solutions are built to run in the cloud (although many can also be placed in a private cloud or on premises); use the newest database technology; incorporate responsive design techniques to allow delivery of content to many groups of internal and external users in a variety of channels; depend on highly sophisticated and fast-search software to speed the delivery of information; and embed content management functionality to enable the collection and preparation of all types of data from an unlimited number of sources.
Many of these solutions also incorporate a KM framework such as knowledge center support to help users roll out and apply their solutions effectively.
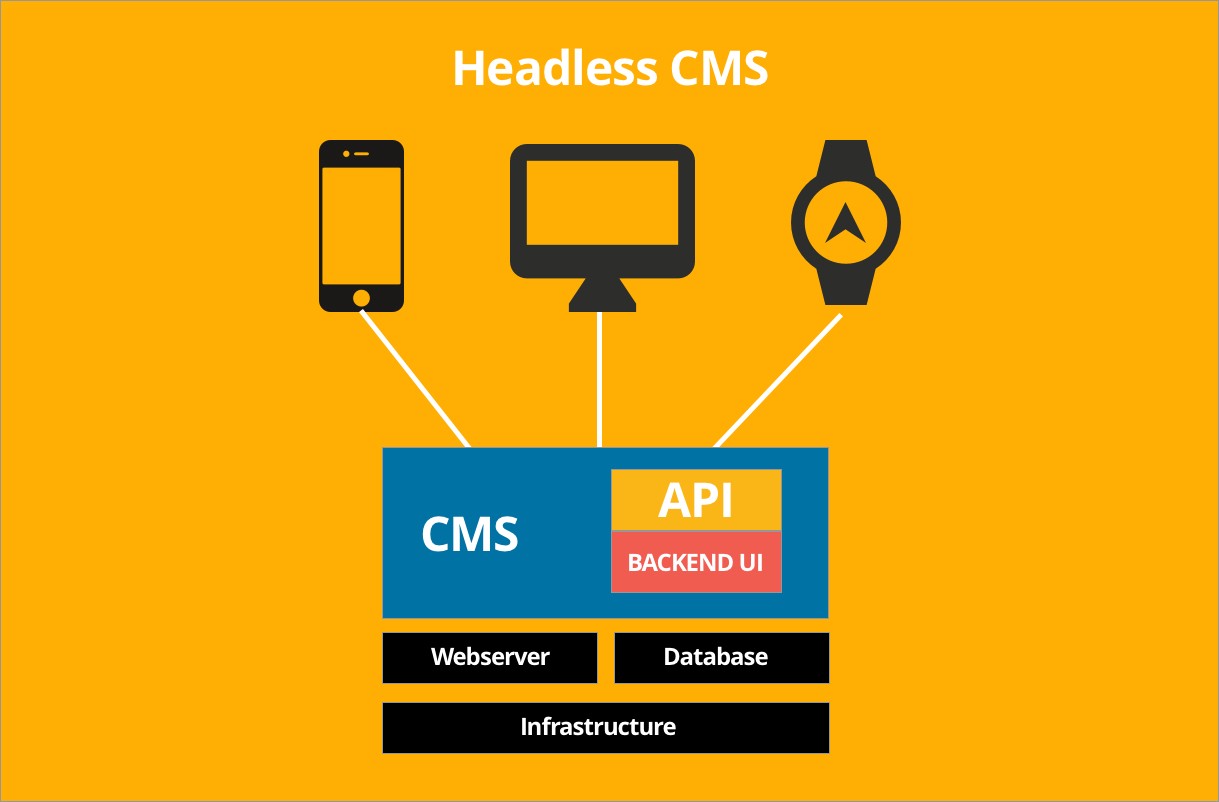
Differentiating between KM, search, and content management software has always been a challenge. In fact, a good KM solution depends on content management techniques to enable it to capture, structure, and properly store data.
KM ensures that the right components of the data are delivered in a manner appropriate for each group (agents, IT staff, back-office employees, executives, customers, partners) and in a format appropriate for each channel (live agent, web self-service, voice self-service, email, chat, SMS, video, social media). When it comes to data sharing, a KM solution is the heart, and it pumps knowledge out to where it is needed, when it is needed, to keep an organization running properly.
Changing KM's Perception and Value Proposition
Major technical innovations during the past few decades are enabling a new generation of KM solutions. But this is only a small part of the developments that are altering the perception of KM.
In the past, KM solutions were sold to customer service, contact centers, technical support, field service, and other departments that were dependent upon having a source of information to address customer inquiries.
The value proposition was that a KM solution could replace or lessen the need for staff training and reduce the average handling time with customers. Essentially, KM solutions were sold to enhance productivity and reduce operating costs while improving service quality and first-contact resolution (FCR).
The problem was that employees did not like using many of the KM solutions because the solutions slowed them down; instead of reducing the average handling time of inquiries and improving FCR, the opposite occurred, and agents were penalized. The solutions came with poorly designed interfaces, and the search capabilities were ineffective.
In addition, agents learned not to rely on a KM solution’s answers because much of the information residing there was either out of date or inaccurate, and the process of keeping knowledge current was cumbersome, time consuming, and costly.
The situation is different today. Companies are anticipating much broader uses for their knowledge bases. Executives have bought into the concept of having a single version of the truth for organization's knowledge, particularly when the information can be rendered appropriately for each group of users.
As a result, the number of potential KM users has increased, which is a significant game changer. Customers are also making it known that they prefer to use self-service over speaking to live agents, making it necessary to have a clean, accurate, and easy-to-update KB.
Additionally, Millennial agents, who are now the primary employee demographic throughout organizations, are wired to look up answers and are happy to use a KM solution, as long as it can quickly give them the accurate information they need. In other words, the current generation of KM solutions is delivering on its promise and has a proven and quantifiable value proposition, when supported by the right enterprise framework and culture.
The KM Competitive Landscape
The fundamental KM concepts still stand, but how they are addressed varies by vendor. Each solution is unique, with an assortment of underlying technology and approaches. Vendors are entering the KM market from many IT sectors, including AI, customer relationship management (CRM), enterprise resource planning (ERP), IT service management (ITSM), workforce optimization (WFO), contact center infrastructure, professional services, and others.
Some vendors sell only a KM solution; many others offer a KM capability as part of a suite of products, but do not offer it on a stand-alone basis.
The market is in the early stages of transformation, and a great deal more change is expected in the next few years. KM has remained more or less the same for decades, but this is expected to change as organizations get serious about creating a single source of knowledge. The opportunities are great for disruptive solutions to enter and transform this sector.
KM Needs a Framework and Best Practices
While the KM offerings have improved substantially, the primary challenge confronting this sector remains the acquisition, maintenance, and delivery of content. A KM solution is effective only if the underlying data is correct; if the data is inaccurate, it doesn’t matter how well organized or how fast and easy to deliver it is.
Moreover, for a KM solution to work, a company needs to create an operating environment where all employees support the concept and practice of KM. It’s more than building a KM culture. An organization must institute a framework supported by internal infrastructure that facilitates the processes. It’s not about rewarding employees for authoring articles and using the KM solution. Instead, KM needs to become an inherent and essential component of what employees do on a daily basis.
Final Thoughts on KM
It’s taken a few decades, but KM is finally in the spotlight. AI is helping to push the KM agenda, and companies are getting on board with the idea of creating a single repository of enterprise knowledge, formal and “tribal”, as they consider its broad benefits for the organization, employees, partners, and customers.
While it’s challenging to implement a KM solution, this is actually the easy part of the effort. More challenging is to set up the organization and processes to succeed with the transformation.
We have 20 years experience in KM. Please contact us today for a free consultation.